Spark application consists of a driver program that runs the user’s main
function and executes various parallel operations on a cluster. The
main abstraction Spark provides is a resilient distributed dataset
(RDD), which is a collection of elements partitioned across the nodes of
the cluster that can be operated on in parallel.
- It is immutable(Read only) in nature. Distributed means, each RDD is divided into multiple partitions.
- Each of these partitions can reside in memory or stored on the disk of different machines in a cluster.
- Basically, RDD in spark is designed as each dataset (String,Lines,rows,objects,collections) in RDD is divided into logical partitions.
- Further, we can say here each partition may be computed on different nodes of the cluster. Moreover, Spark RDDs contain user-defined classes.
- RDD can cached and persisted.
- Transformation act on RDDs to create a new RDD.
- Action analyze RDDs and provide result.
RDD's Features
- In-memory computation:-The data inside RDD are stored in memory. Keeping the data in-memory improves the performance by an order of magnitudes.
- Lazy Evaluation:- The data inside RDDs are not evaluated on the go.The changes or the computation is performed only after an action is triggered.
- Fault Tolerance:- Upon the failure of worker node, using lineage of operations we can re-compute the lost partition of RDD from the original one. Thus, we can easily recover the lost data.
- Immutability:- RDD'S are immutable in nature meaning once we create an RDD we can not manipulate it. And if we perform any transformation, it creates new RDD.
- Persistence:- We can store the frequently used RDD in in-memory and we can also retrieve them directly from memory without going to disk, this speedup the execution. We can perform Multiple operations on the same data, this happens by storing the data explicitly in memory by calling persist() or cache() function.
- Partitioning:- RDD partition the records logically and distributes the data across various nodes in the cluster. The logical divisions are only for processing and internally it has no division. Thus, it provides parallelism.
- Parallel:- Rdd, process the data parallelly over the cluster.
- Location-Stickiness:- RDDs are capable of defining placement preference to compute partitions. Placement preference refers to information about the location of RDD. The DAGScheduler places the partitions in such a way that task is close to data as much as possible. Thus speed up computation.
- Coarse-grained Operation:- We apply coarse-grained transformations to RDD. Coarse-grained meaning the operation applies to the whole dataset not on an individual element in the data set of RDD.
- Typed:- We can have RDD of various types like: RDD [int], RDD [long], RDD [string].
- No limitation:- we can have any number of RDD. there is no limit to its number. the limit depends on the size of disk and memory.
Why RDD?
When it comes to iterative distributed computing, i.e.
processing data over multiple jobs in computations such as Logistic
Regression, K-means clustering, Page rank algorithms, it is fairly
common to reuse or share the data among multiple jobs or you may want to
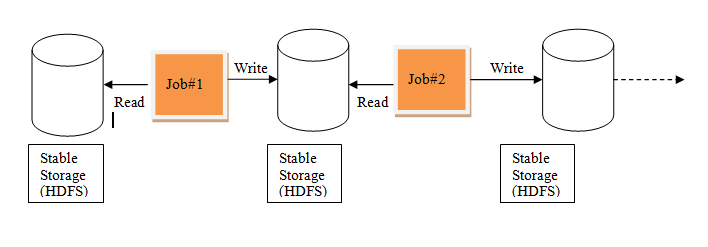
do multiple ad-hoc queries over a shared data set. There is an underlying problem with data reuse or data
sharing in existing distributed computing systems (such as MapReduce)
and that is , you need to store data in some intermediate stable
distributed store such as HDFS or Amazon S3. This makes the overall
computations of jobs slower since it involves multiple IO operations,
replications and serializations in the process.
Iterative Processing in MapReduce
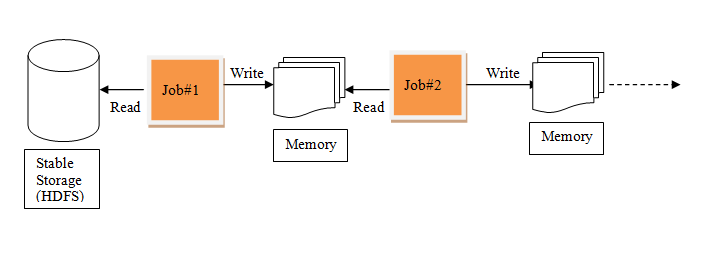
RDDs , tries to solve these problems by enabling fault tolerant distributed In-memory computations.
When to use RDDs?
Consider these scenarios or common use cases for using RDDs when:
- you want low-level transformation and actions and control on your dataset;
- your data is unstructured, such as media streams or streams of text;
- you want to manipulate your data with functional programming constructs than domain specific expressions;
- you don’t care about imposing a schema, such as columnar format, while processing or accessing data attributes by name or column.
- If you don't care about optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
No comments:
Post a Comment